
RAG: Революция в мире искусственного интеллекта — всё, что нужно знать о технологии будущего!
Что такое RAG и почему это важно
RAG (Retrieval-Augmented Generation) — это современная технология искусственного интеллекта, которая переводится как «генерация с дополненной выборкой». Это архитектурный подход, объединяющий мощь больших языковых моделей (LLM) с внешними, авторитетными базами знаний.
Проще говоря, RAG — это способ "научить" ИИ не выдумывать ответы, а находить их в проверенных источниках и на их основе генерировать осмысленный текст. Если представить обычную языковую модель как очень эрудированного, но немного забывчивого эксперта, который не читал ничего нового за последние пару лет, то RAG дает этому эксперту доступ к огромной, постоянно обновляемой библиотеке.
Как работает система RAG: под капотом технологии
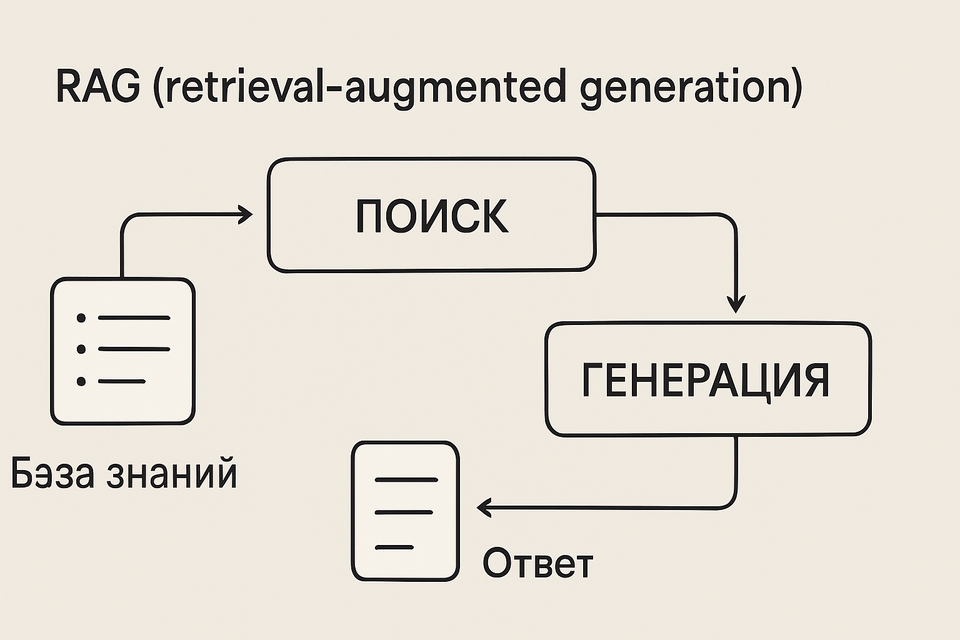
Основные компоненты технологии
RAG состоит из трех основных элементов, заложенных в самом названии — Retrieval (поиск), Augmented (дополнение) и Generation (генерация):
Retrieval (Поиск) — элемент отвечает за поиск информации, релевантной запросу пользователя к нейросети. Поиск может выполняться по любой базе данных, например, по справочнику технической поддержки с часто задаваемыми клиентами вопросами.
Augmented (Дополнение) — дополнение запроса пользователя к нейросети найденной информацией из связанной базы данных.
Generation (Генерация) — генерация итогового запроса к нейросети с дополнительными данными, которые могут содержать ответ на вопрос пользователя.
Пошаговая работа системы
Процесс работы RAG можно разделить на несколько этапов:
- Сбор и подготовка данных — создается база знаний из документов, на которой будет базироваться поиск
- Чанкирование — документы разбиваются на небольшие фрагменты (чанки) размером от 100 до 1000 слов
- Создание эмбеддингов — чанки преобразуются в векторное представление с помощью специальных моделей
- Векторная база данных — векторы собираются в единую БД для хранения скрытых в них данных
- Поиск релевантной информации — при получении запроса пользователя система находит наиболее подходящие чанки
- Генерация ответа — найденная информация объединяется с запросом и передается в языковую модель для формирования ответа
Векторные базы данных и эмбеддинги
Сердце системы RAG — это векторное хранилище, где текстовые данные представлены в виде числовых векторов. Документы разбиваются на небольшие логические фрагменты — абзацы или предложения, каждый из которых преобразуется в вектор с помощью обученной модели-энкодера.
Эмбеддинги — это математическое представление текста в виде многомерных числовых векторов, которые получаются путем обработки исходного текста через нейросеть. Семантически похожие тексты имеют близкие векторные представления, что позволяет находить релевантную информацию по смыслу, а не просто по совпадению ключевых слов.
Преимущества RAG для бизнеса и пользователей
Актуальность информации
RAG позволяет получать актуальную информацию в реальном времени. В отличие от обычных языковых моделей, которые могут "застрять в прошлом", RAG подключается к живым данным из внешних источников, гарантируя, что ответы будут актуальными и релевантными.
Снижение "галлюцинаций"
Одна из главных проблем больших языковых моделей — склонность к "галлюцинациям" (генерация неверной или вымышленной информации). RAG помогает модели избежать этого, извлекая точные, проверенные данные из надежных источников.
Экономическая эффективность
С RAG нет необходимости постоянно переобучать всю языковую модель при появлении новой информации. Вместо этого модель может извлекать соответствующие данные в режиме реального времени, что делает её более ресурсоэффективным подходом.
Доменная специализация
RAG позволяет языковым моделям "говорить на языке каждой отрасли". Подключая модель к специализированным базам знаний, можно получать экспертную информацию в таких областях, как здравоохранение, финансы или юридические услуги.
Проблемы и ограничения технологии
Точность поиска
Согласно экспертным оценкам, векторный поиск корректно находит нужный фрагмент документации лишь в 30% случаев. Остальные 70% запросов возвращают нерелевантные или неточные результаты.
Основные причины ошибок
Большая база знаний — при обширном объеме документации некоторые эмбеддинги могут пересекаться, что затрудняет выбор оптимального совпадения.
Нечеткие формулировки вопросов — пользователи часто используют сленг, обрывочные формулировки и неконкретные описания проблем.
"Шум" в базе знаний — документация может быть дублирующейся и плохо структурированной.
Технические ограничения
RAG не исключает риск "галлюцинаций" полностью — модель может создавать неправдоподобные или недостоверные ответы. Качество итогового результата зависит от правильной настройки алгоритма поиска, оценки релевантности и подбора источников.
Практические применения RAG в бизнесе
Техническая поддержка
RAG активно используется для создания чат-ботов технической поддержки. Боты парсят документацию и инструкции, отвечая на обращения пользователей как специалисты первой линии поддержки.
Корпоративные ассистенты
HR-ассистенты помогают новичкам разобраться с внутренними процессами, политиками дизайна, формами отпусков. Юридические консультанты ищут шаблоны договоров и помогают находить похожие документы по ключевым условиям.
Образование и обучение
RAG-системы создают персонализированные образовательные платформы, которые могут адаптировать контент под конкретные потребности учащихся, предоставляя актуальную информацию из различных источников.
Маркетинг и продажи
В маркетинге RAG помогает в подборе формулировок, текстов и презентаций, используя актуальные данные о продуктах и рынке. Системы могут генерировать персонализированный контент для разных сегментов аудитории.
Настройка и внедрение RAG-системы
Выбор технологического стека
Для создания RAG-системы необходимы следующие компоненты:
- Эмбедер — модели для создания векторных представлений (BGE-M3, text-embedding-3-large, FRIDA)
- Векторная база данных — для хранения эмбеддингов (FAISS для небольших объемов, специализированные решения для больших данных)
- Ретривер — система поиска релевантных чанков
- Реранкер — для упорядочивания найденных чанков по релевантности
- LLM — для генерации финального ответа
Этапы настройки
- Подготовка данных — чистка и форматирование исходных документов
- Чанкирование — разбивка текста на фрагменты размером ~1000 токенов
- Создание эмбеддингов — преобразование чанков в векторы
- Индексация — загрузка векторов в базу данных
- Тестирование и оптимизация — проверка качества работы системы
Рекомендации по улучшению качества
Для повышения точности RAG-системы рекомендуется:
- Дообучение модели эмбеддингов на специфических данных домена
- Настройка параметров чанкирования под конкретные типы документов
- Использование гибридного поиска (векторный + полнотекстовый)
- Внедрение механизмов фильтрации и ранжирования результатов
Будущее RAG: тренды и перспективы 2025
Мультимодальные RAG-системы
В будущем ожидается развитие мультимодальных RAG, которые смогут извлекать информацию из различных типов данных: изображений, видео, аудио, таблиц и графиков. Это позволит создавать еще более интеллектуальные системы, способные понимать и обрабатывать информацию в любом формате.
Интеграция с AI-агентами
RAG станет ключевым компонентом для создания более сложных и автономных AI-агентов, способных не только отвечать на вопросы, но и самостоятельно выполнять комплексные задачи, взаимодействовать с различными системами и принимать решения.
Рыночные перспективы
По данным исследований, доля приложений с RAG выросла с ~31% до 51% всего за 2024 год — более половины компаний теперь используют RAG. Это означает, что компании предпочитают подмешивать свои данные в LLM при инференсе, нежели заниматься долгим и дорогим обучением под каждую задачу.
Технологические улучшения
Ожидается развитие продвинутых алгоритмов извлечения информации, способных учитывать не только семантическое сходство, но и логические связи, причинно-следственные отношения и временные зависимости между данными.
Заключение: RAG как стандарт будущего
RAG уже стал бизнес-стандартом в AI-решениях. Компании, которые внедряют эту технологию, получают не просто чат-ботов, а мощные инструменты автоматизации и анализа.
Технология RAG превращает статичные языковые модели в живые базы знаний с доступом к актуальной информации. В 2025 году RAG продолжит эволюционировать, предлагая компаниям все более мощные и интеллектуальные инструменты для оптимизации бизнес-процессов.
Согласно исследованию ICT.Moscow, 46% российских разработчиков называют среди приоритетных задач использование RAG для повышения точности генерации. Это подтверждает, что RAG — не просто технологический тренд, а стратегическая необходимость для компаний, стремящихся остаться конкурентоспособными в цифровую эпоху.

Комментарии ()