
Всё о моделях логического мышления

Искусственный интеллект (ИИ) переживает настоящий бум, и модели логического мышления (Reasoning LLMs) — это новый шаг вперёд. Они не просто отвечают на вопросы, а думают, как человек, разбирая задачу по шагам и находя логичные решения. Хотите узнать, как они работают, где их используют и как извлечь из них максимум? В этой статье мы разберём всё: от архитектуры моделей до их применения в реальной жизни. Погрузимся в мир ИИ, который меняет наше представление о технологиях!
Что такое Reasoning LLMs?
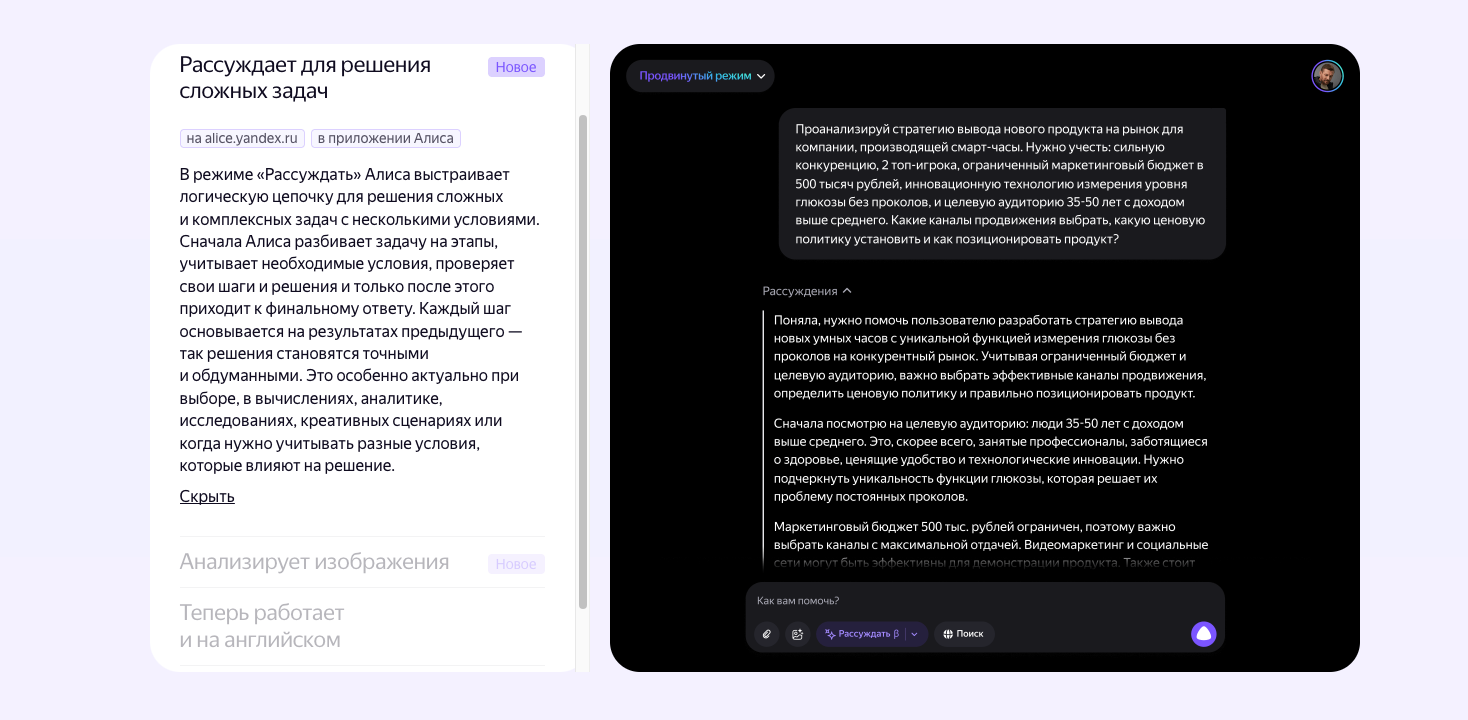
Модели логического мышления (Reasoning Large Language Models, или Reasoning LLMs) — это продвинутые языковые модели, которые специально обучены для решения сложных задач с помощью логического анализа. В отличие от обычных моделей, таких как GPT-4 или Llama 3.1, которые могут выдавать ответы сразу, Reasoning LLMs действуют иначе: они разбивают задачу на части, анализируют их и строят цепочку рассуждений (Chain-of-Thought, CoT). Это позволяет им справляться с задачами, требующими глубокого анализа, например, вычислить сумму первых 50 простых чисел или спланировать сложное исследование.
Попробуйте задать модели вроде OpenAI o1 или Claude 3.7 Sonnet вопрос: «Какова сумма первых 50 простых чисел?» Они не только дадут ответ, но и покажут, как пришли к нему, написав, например, Python-код для расчёта. Это делает их незаменимыми для задач, где важна не только точность, но и прозрачность решения.
Цепочка рассуждений (Chain-of-Thought, CoT) — метод, при котором модель разбивает задачу на последовательные шаги, чтобы прийти к логически обоснованному решению.
Как работают Reasoning LLMs?
Принципы работы: как модели «думают»
Главное отличие Reasoning LLMs — способность «думать» пошагово, почти как человек. Обычные языковые модели предсказывают следующее слово на основе предыдущих, что иногда приводит к ошибкам в задачах, требующих логики, например, в математических расчётах или анализе сложных текстов. Reasoning LLMs, напротив, тратят больше времени на анализ задачи. Например, OpenAI отмечает, что их модель o1 «обдумывает проблему, пробуя разные стратегии и исправляя ошибки» перед тем, как выдать ответ.
Этот процесс включает несколько этапов:
- Анализ задачи: Модель переформулирует условие, выделяя ключевые элементы.
- Декомпозиция: Сложная задача разбивается на подзадачи.
- Систематическое решение: Модель решает каждую часть шаг за шагом.
- Альтернативные подходы: При необходимости рассматриваются разные варианты решения.
- Самопроверка: Модель проверяет промежуточные результаты на ошибки.
- Самокоррекция: Если найдена ошибка, модель возвращается назад и исправляет её.
Такой подход резко повышает точность. Например, добавление фразы «Давай подумаем пошагово» к запросу для обычной модели увеличивает её точность на математическом тесте MultiArith с 17,7% до 78,7%. Для Reasoning LLMs этот процесс встроен автоматически, что делает их особенно мощными.
Архитектура: что внутри?
Reasoning LLMs основаны на архитектуре Transformer, как и обычные языковые модели. Transformer использует механизм self-attention (само-внимание), который позволяет модели анализировать весь контекст задачи сразу, а не по частям. Это помогает, например, соотнести текущий шаг решения с условием, упомянутым ранее, или учесть промежуточные выводы.
Однако сама по себе архитектура Transformer не гарантирует логического мышления. Ключевую роль играет обучение:
- Обучение с подкреплением (RLHF): Модели, такие как OpenAI o1 и DeepSeek R1, обучаются с помощью подкрепления, где их «вознаграждают» за правильные логические решения. Это учит модель рассуждать, а не просто выдавать наиболее вероятный ответ.
- Supervised Fine-Tuning (SFT): Модели дообучают на примерах пошаговых решений, что помогает им имитировать логический подход.
- Mixture of Experts (MoE): Некоторые модели, например DeepSeek R1, используют подход MoE, где разные «эксперты» (подмодели) отвечают за разные типы задач. Это позволяет масштабировать модель до 671 миллиарда параметров, активируя лишь часть (около 37 млрд) для каждого запроса.
- Большое контекстное окно: Модели вроде Claude 3.7 Sonnet поддерживают до 200 000 токенов, что позволяет удерживать в памяти большие объёмы данных, такие как кодовые базы или длинные документы.
Эти элементы вместе создают модель, способную не только обрабатывать информацию, но и рассуждать над ней, как настоящий аналитик.
Transformer — архитектура нейронной сети, используемая в языковых моделях, которая обрабатывает текст с помощью механизма само-внимания, учитывая взаимосвязи между словами в предложении.
Лучшие модели Reasoning LLMs
На 2025 год выделяются три ведущие модели, которые задают тон в области логического мышления: OpenAI o1, DeepSeek R1 и Claude 3.7 Sonnet. Давайте разберём их особенности, сильные и слабые стороны.
OpenAI o1: мастер сложных задач
OpenAI o1, представленная в сентябре 2024 года, создана для решения задач, с которыми не справлялись предыдущие модели, такие как GPT-4. Она показывает впечатляющие результаты: решает 83% задач отборочного экзамена Международной математической олимпиады (IMO) против 13% у GPT-4 и достигает 89% перцентиля на соревнованиях по программированию Codeforces.
- Особенности: Основана на GPT-4o, но с упором на обучение через RLHF для логических задач. Модель использует test-time compute, тратя больше времени на сложные задачи. Также доступна облегчённая версия o1-mini, которая дешевле и быстрее, но ориентирована на кодирование.
- Сильные стороны: Превосходство в математике, программировании и научных задачах уровня PhD. Прозрачные цепочки рассуждений.
- Слабые стороны: Высокая стоимость, ограниченные мультимодальные возможности (например, изначально не поддерживает обработку изображений), меньшая универсальность в повседневных диалогах по сравнению с GPT-4o.
- Доступ: Через ChatGPT (Plus/Enterprise) и API.
Test-time compute — подход, при котором модель тратит больше вычислительных ресурсов на анализ задачи во время ответа, улучшая качество решения.
DeepSeek R1: открытая альтернатива
DeepSeek R1, представленная в январе 2025 года, — это open-source модель, которая конкурирует с проприетарными аналогами. С 671 миллиардом параметров (из которых 37 млрд активны для каждого токена) она использует архитектуру MoE, что делает её экономичной и мощной.
- Особенности: Обучена через RLHF и SFT, что дало ей способности к самопроверке и рефлексии. Доступны дистиллированные версии (1.5B–70B параметров), которые сохраняют логику R1, но работают быстрее.
- Сильные стороны: Открытость, низкая стоимость (около $0.55 за миллион входных токенов против $3 у Claude), высокая точность в математике (97,3% на AIME 2024) и программировании (49,2% на SWE-bench).
- Слабые стороны: Отсутствие мультимодальности (не работает с изображениями), требует мощных вычислительных ресурсов для локального запуска.
- Доступ: Через Hugging Face API или локально.
Claude 3.7 Sonnet: гибридный подход
Claude 3.7 Sonnet, выпущенная в феврале 2025 года Anthropic, — это гибридная модель, которая сочетает быстрые ответы и глубокое мышление. Пользователь может переключаться между обычным режимом и Extended Thinking (до 128 000 токенов на размышления).
- Особенности: Поддерживает контекст до 200 000 токенов и мультимодальность (работа с изображениями и PDF). В режиме Thinking Mode модель показывает шаги рассуждений.
- Сильные стороны: Лидирует в программировании (70,3% на SWE-bench с промптом), хорош для бизнес-применений, удобен в интеграции (Amazon Bedrock, Google Vertex AI).
- Слабые стороны: Высокая стоимость ($3–$15 за миллион токенов), ограниченный бесплатный доступ, медленная работа при большом контексте.
- Доступ: Через Claude.ai, API, облачные платформы.
Сравнение производительности
| Модель | Математика (AIME 2024) | Программирование (SWE-bench) | Контекст (токены) | Мультимодальность |
|---|---|---|---|---|
| OpenAI o1 | 96,4% | 48,9% | Не указано | Нет |
| DeepSeek R1 | 97,3% | 49,2% | 128 000 | Нет |
| Claude 3.7 Sonnet | ~84,8% (graduate-level) | 70,3% (с промптом) | 200 000 | Да |
Эти модели задают стандарт качества, но выбор зависит от задачи: Claude для бизнес-применений, DeepSeek для экономии, o1 для олимпиадных задач.
Примеры использования для обычных пользователей
Модели логического мышления не только для программистов или учёных — они могут помочь каждому в повседневной жизни. Вот несколько примеров, как обычные пользователи могут применять Reasoning LLMs, чтобы упростить свои задачи.
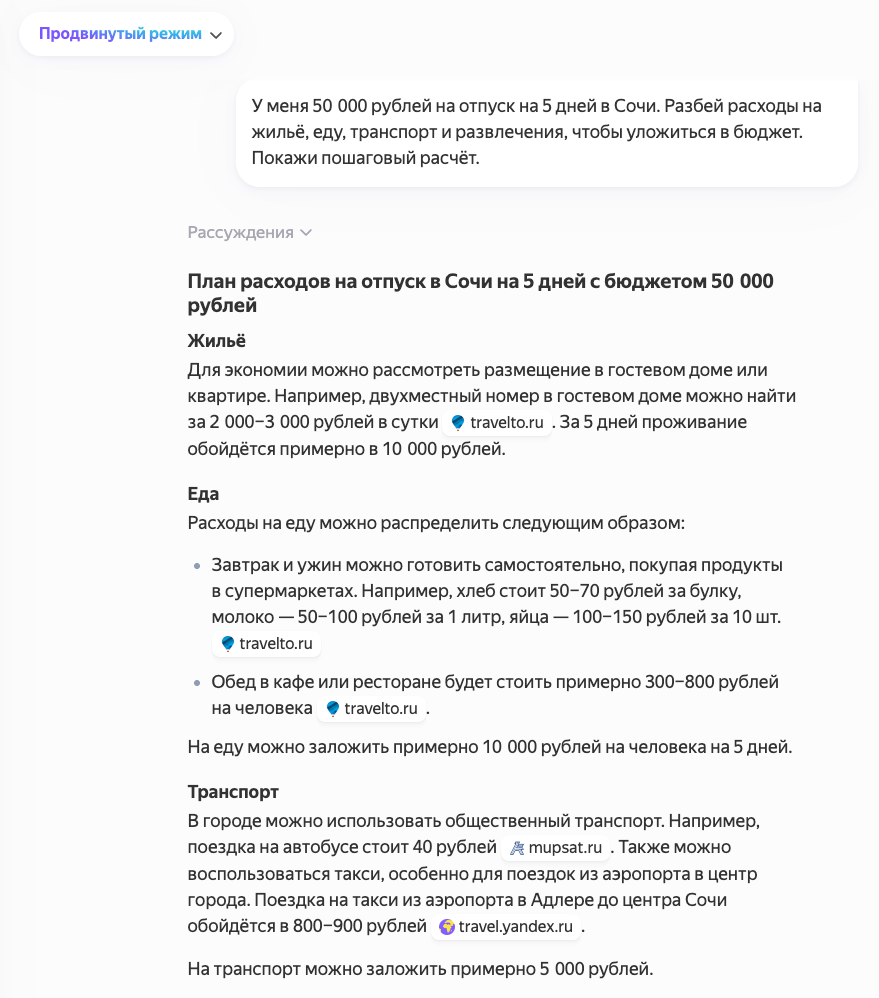
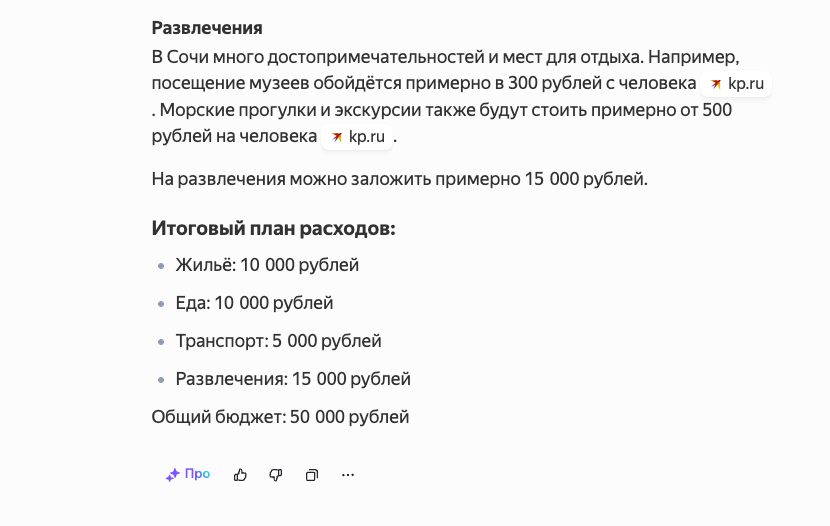
Планирование бюджета для отпуска
Представьте, что вы планируете отпуск, но бюджет ограничен. Вы можете попросить модель, например, Claude 3.7 Sonnet, помочь составить план. Задайте вопрос: «У меня 50 000 рублей на отпуск на 5 дней в Сочи. Разбей расходы на жильё, еду, транспорт и развлечения, чтобы уложиться в бюджет. Покажи пошаговый расчёт.» Модель:
- Разделит бюджет на категории (например, 40% на жильё, 30% на еду, 20% на транспорт, 10% на развлечения).
- Предложит варианты: недорогие отели, средние цены на кафе, стоимость билетов на автобусы.
- Проверит, чтобы сумма не превысила 50 000 рублей, и предложит корректировки, если где-то перерасход.
В итоге вы получите чёткий план, который можно сразу использовать, а прозрачные шаги помогут понять, где можно сэкономить.
Ниже пример Яндекс GPT в рассудительном режиме:
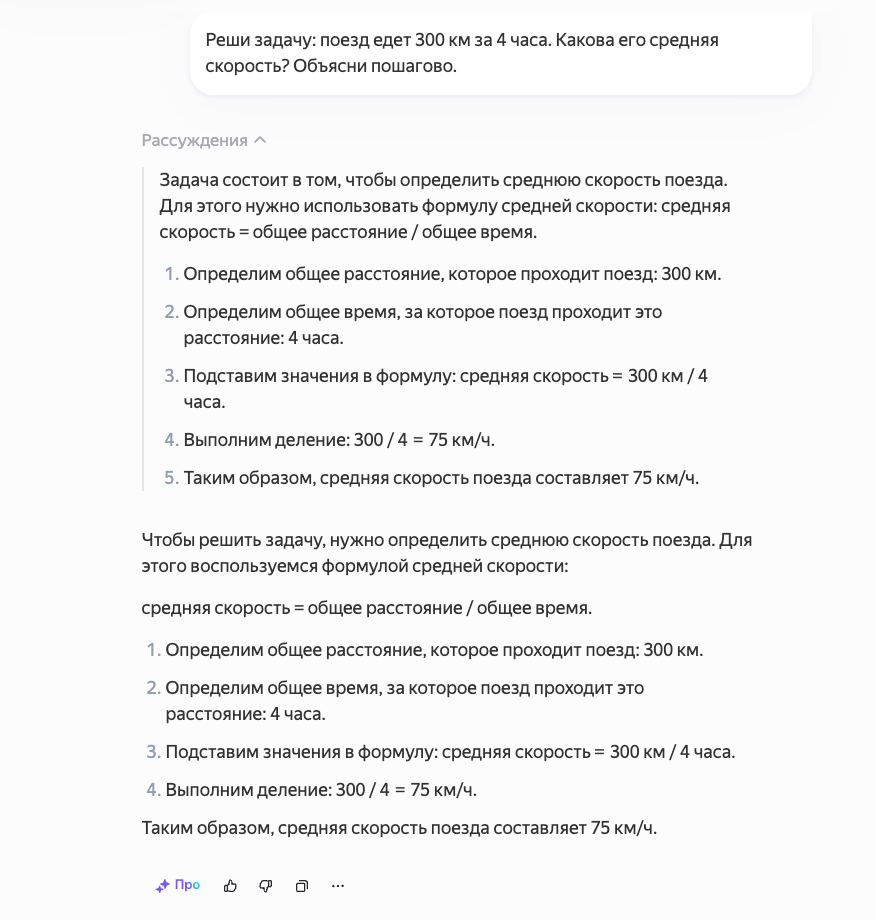
Решение школьных задач
Если ваш ребёнок застрял на домашнем задании по математике, Reasoning LLMs, такие как OpenAI o1, могут стать отличным помощником. Например, задайте вопрос: «Реши задачу: поезд едет 300 км за 4 часа. Какова его средняя скорость? Объясни пошагово.» Модель:
- Определит формулу: скорость = расстояние / время.
- Подставит значения: 300 км / 4 ч = 75 км/ч.
- Проверит ответ, убедившись, что 75 км/ч × 4 ч = 300 км.
- Объяснит решение простыми словами, чтобы ребёнок понял.
Это не только даст правильный ответ, но и научит ребёнка разбирать задачи самостоятельно.
Ниже пример Яндекс GPT в рассудительном режиме:
Планирование сложного мероприятия
Допустим, вы организуете семейный праздник на 20 человек и хотите всё продумать. Попросите DeepSeek R1: «Составь план подготовки к семейному пикнику на 20 человек. Учти меню, список покупок, развлечения и распредели задачи между тремя организаторами. Покажи шаги.» Модель:
- Разделит задачу на этапы: выбор места, меню, закупки, развлечения.
- Предложит меню (например, бутерброды, салаты, гриль), рассчитав количество продуктов.
- Составит список покупок с примерными ценами.
- Распределит задачи: один покупает еду, второй организует игры, третий отвечает за транспорт.
- Проверит, чтобы всё было реалистично и уложилось в бюджет.
Вы получите готовый план, который можно сразу воплотить в жизнь.
Анализ сложных текстов
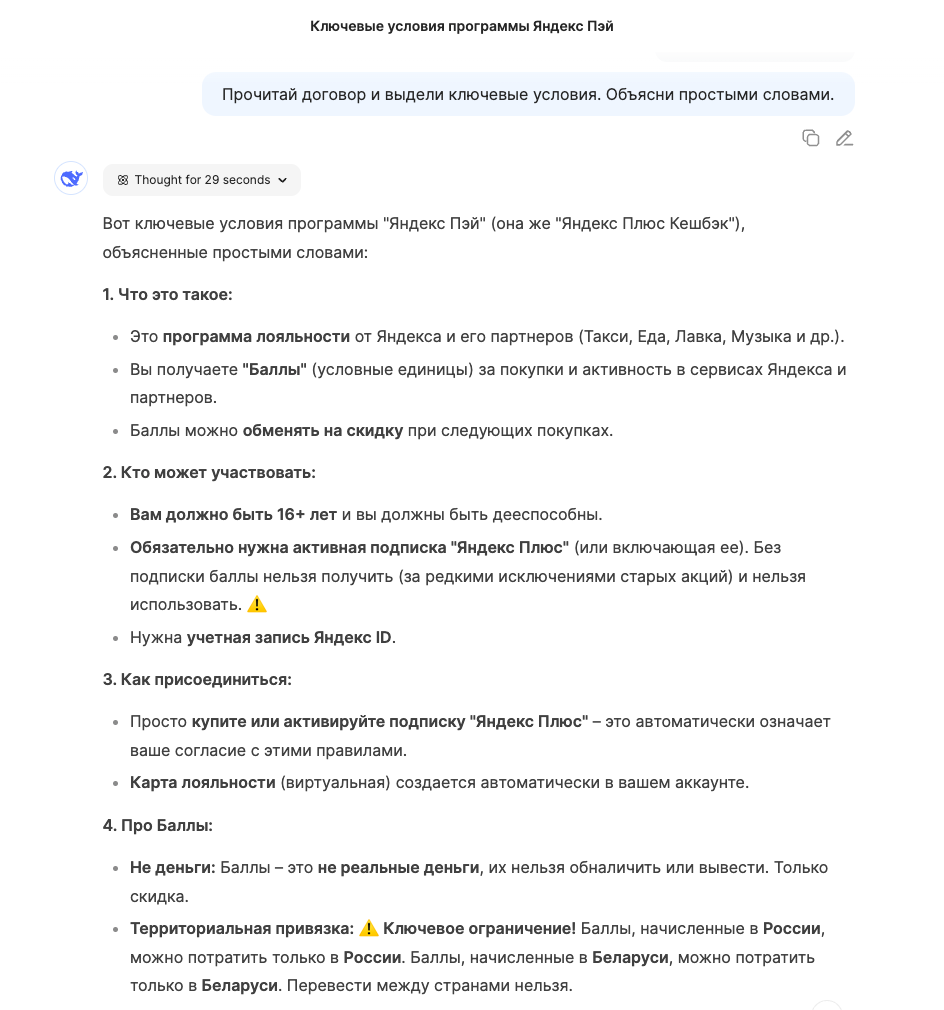
Если вам нужно разобраться в сложном документе, например, в договоре аренды, Claude 3.7 Sonnet (с поддержкой PDF) поможет. Загрузите документ и спросите: «Прочитай договор и выдели ключевые условия: стоимость, сроки, штрафы. Объясни простыми словами.» Модель:
- Просмотрит текст, выделяя важные пункты.
- Перескажет их простым языком: «Аренда стоит 30 000 рублей в месяц, срок — 1 год, штраф за просрочку — 500 рублей в день».
- Укажет, если что-то в договоре кажется неоднозначным, и предложит уточнить у юриста.
Это сэкономит время и поможет избежать ошибок при подписании.
Ниже пример Deepseek в рассудительном режиме:
Помощь в принятии решений
Когда вы стоите перед сложным выбором, например, покупать новую машину или отремонтировать старую, Reasoning LLMs могут взвесить плюсы и минусы. Спросите OpenAI o1: «У меня машина 2010 года, ремонт стоит 100 000 рублей, новая — 1 500 000 рублей. Проанализируй, что выгоднее, учитывая расходы на 5 лет. Покажи расчёт.» Модель:
- Учтёт стоимость ремонта, обслуживания старой машины, её остаточную стоимость.
- Рассчитает расходы на новую машину, включая кредит, страховку, топливо.
- Сравнит оба варианта, показав, что, например, ремонт выгоднее, если ездить менее 3 лет.
- Проверит расчёты, чтобы исключить ошибки.
Такой анализ поможет принять обоснованное решение без лишних эмоций.
Где применяются Reasoning LLMs?
Модели логического мышления находят применение в самых разных областях благодаря их способности анализировать и планировать. Вот ключевые сценарии для профессионалов:
- Агентные системы: Reasoning LLMs помогают автономным агентам планировать действия, например, в системах глубокого поиска (Deep Research Agentic Systems). Модель разбивает запрос на подзадачи и управляет процессом (Orchestrator-Worker Agent).
- Agentic RAG: Системы, сочетающие поиск информации с логическим анализом, используют Reasoning LLMs для обработки сложных запросов и работы с большими базами знаний.
- LLM-as-a-Judge: Модели оценивают результаты других систем, давая обратную связь и оптимизируя процессы. Это полезно для автоматической проверки качества.
- Визуальное мышление: Модели вроде Claude 3.7 Sonnet могут анализировать изображения, решать визуальные головоломки или выполнять задачи, такие как обрезка и поворот картинок.
- Другие применения:
- Анализ больших наборов данных в технических и научных областях.
- Отладка кода и разработка алгоритмов.
- Научные задачи: математические расчёты, планирование экспериментов.
- Синтез литературы и обзоры исследований.
- Проверка качества данных и создание оптимизированных инструкций.
Агентные системы — программы, которые автономно выполняют задачи, принимая решения на основе данных и инструкций.
Agentic RAG (Retrieval-Augmented Generation) — технология, сочетающая поиск информации с логическими рассуждениями для работы с большими базами данных.
Факторы, влияющие на точность
Точность Reasoning LLMs зависит от нескольких факторов:
- Качество обучения: Модели, обученные на больших наборах данных с примерами пошаговых решений, лучше справляются с задачами. Например, o1 обучали на математических и научных задачах, что повысило её точность на олимпиадах.
- Размер модели: Большие модели (>100 млрд параметров) лучше проявляют логические способности благодаря эмерджентным свойствам.
- Промптинг: Чёткие инструкции, такие как «Решай пошагово» или «Проверь ответ», значительно повышают точность. Few-shot prompting (1–2 примера решения) и role prompting («Ты математик») также помогают.
- Параметры инференса: Низкая temperature (0) снижает случайные ошибки, а метод self-consistency (многократная генерация ответа) повышает надёжность.
- Инструменты: Подключение внешних инструментов (API, калькуляторы) улучшает точность, позволяя модели проверять факты или вычисления.
- Самопроверка: Модели, обученные проверять свои решения, реже ошибаются. Например, o1 подставляет корни уравнений, чтобы убедиться в их правильности.
- Настройка инструкций (Alignment): Сбалансированное RLHF предотвращает отказы от корректных вопросов и сохраняет объективность.
Эмерджентные свойства — способности модели, которые проявляются только при достижении определённого масштаба, например, логическое мышление у моделей с сотнями миллиардов параметров.
Практические рекомендации
Чтобы получить максимум от Reasoning LLMs, следуйте этим советам:
- Выбирайте модель под задачу: Используйте обычные LLM для простых вопросов, а Reasoning LLMs — для сложных задач, таких как программирование или анализ данных.
- Чёткие запросы: Формулируйте задачу ясно, указывая, что нужно «решать пошагово» или «показать ход решения». Это повышает точность и прозрачность.
- Структурируйте ввод: Разбивайте задачу на части или нумеруйте шаги, чтобы модель следовала вашей логике. Например: «1) Данные… 2) Найти…».
- Контролируйте глубину анализа: Для быстрых ответов просите «короткое решение», для глубокого — включайте режимы вроде Extended Thinking (Claude) или high effort (o1).
- Проверяйте ответы: Для критичных задач просите модель перепроверить решение или используйте другую модель/инструмент для сравнения.
- Self-consistency: Запрашивайте решение несколько раз и выбирайте наиболее частый ответ, чтобы повысить надёжность.
- Интеграция с инструментами: Используйте фреймворки вроде LangChain для подключения моделей к базам знаний или API, чтобы улучшить анализ.
- Meta-prompting: Попросите модель улучшить ваш запрос, например: «Как переформулировать задачу для лучшего ответа?».
- Следите за обновлениями: Новые версии моделей (например, Claude 4 или DeepSeek R2) могут улучшить результаты. Тестируйте их на своих задачах.
- Баланс затрат: Для экономии сначала пробуйте обычные модели, а Reasoning LLMs подключайте только для сложных задач.
Ограничения и вызовы
Несмотря на мощь, Reasoning LLMs имеют свои слабости:
- Качество вывода: Модели могут генерировать повторяющийся или смешанный контент. Это решается чёткими инструкциями и структурированным форматированием.
- Пере- и недомыслие: Без точных запросов модель может либо слишком углубляться, либо упрощать задачу. Разбивайте задачу на подзадачи для контроля.
- Стоимость и задержки: Reasoning LLMs дороже и медленнее обычных моделей. Оптимизируйте запросы или используйте потоковую передачу токенов.
- Ограниченные вызовы инструментов: Некоторые модели (например, DeepSeek R1) пока плохо справляются с параллельными вызовами инструментов, что ограничивает их в агентных системах.
- Ошибки: Даже лучшие модели могут ошибаться. Прозрачность цепочек рассуждений помогает их выявлять, но проверка всё равно нужна.
Будущее Reasoning LLMs
Модели логического мышления — это шаг к ИИ, который не только отвечает, но и принимает решения, взаимодействуя с реальным миром. OpenAI o1, DeepSeek R1 и Claude 3.7 Sonnet показывают, как далеко зашёл прогресс: от олимпиадных задач до автоматизации бизнес-процессов. В будущем улучшение вызовов инструментов, мультимодальности и оптимизация скорости сделают их ещё мощнее. Уже сейчас они становятся виртуальными экспертами, которые могут думать над задачей столько, сколько нужно, не теряя внимательности. Следите за новыми версиями — возможно, скоро мы увидим Claude 4 или DeepSeek R2, которые перевернут игру!
Где можно попробовать
- Алиса от Яндекса стала поддерживать рассудительную модель в платной подписке
- DeepSeek бесплатно доступен в России
- Qwen поддерживает режим мышления и доступен в России



Комментарии ()