
Вышел DeepSeek V4
Пока индустрия искусственного интеллекта, словно зачарованная, продолжает следить за гонкой параметров и громкими релизами от OpenAI и Google DeepMind, китайская DeepSeek делает ход, который на первый взгляд выглядит почти скромно. Однако за этой внешней сдержанностью скрывается нечто куда более амбициозное — попытка переписать саму логику развития языковых моделей.
Если ранние обсуждения DeepSeek V4 вращались вокруг эффективности и снижения стоимости, то опубликованный технический документ раскрывает куда более глубокий сдвиг: речь уже не просто об оптимизации, а о новой архитектурной философии, в которой масштаб и интеллект перестают быть прямыми синонимами.
Миллион токенов как новый горизонт
Самое заметное — и, пожалуй, самое недооценённое — достижение DeepSeek V4 заключается в поддержке контекста длиной до одного миллиона токенов. Эта цифра звучит почти абстрактно, но за ней скрывается фундаментальный сдвиг: модели начинают работать не с фрагментами текста, а с целыми массивами информации, сопоставимыми с книгами, кодовыми базами и даже сложными многодокументными исследованиями.
И здесь важно не только «что», но и «как». В отличие от традиционных подходов, упирающихся в квадратичную сложность attention-механизмов, DeepSeek внедряет гибридную архитектуру внимания — комбинацию Compressed Sparse Attention и Heavily Compressed Attention. Эта система, как следует из описания, буквально «сжимает» память модели, позволяя ей оперировать гигантскими последовательностями без экспоненциального роста затрат.
На уровне практики это означает, что задачи, которые раньше требовали сложной нарезки данных или внешних инструментов, могут быть решены внутри одной модели — от анализа длинных юридических документов до агентных сценариев с длительной памятью.
Эффективность, доведённая до предела
Но куда более интригующим оказывается другое: DeepSeek V4 не просто работает с длинным контекстом — он делает это радикально дешевле.
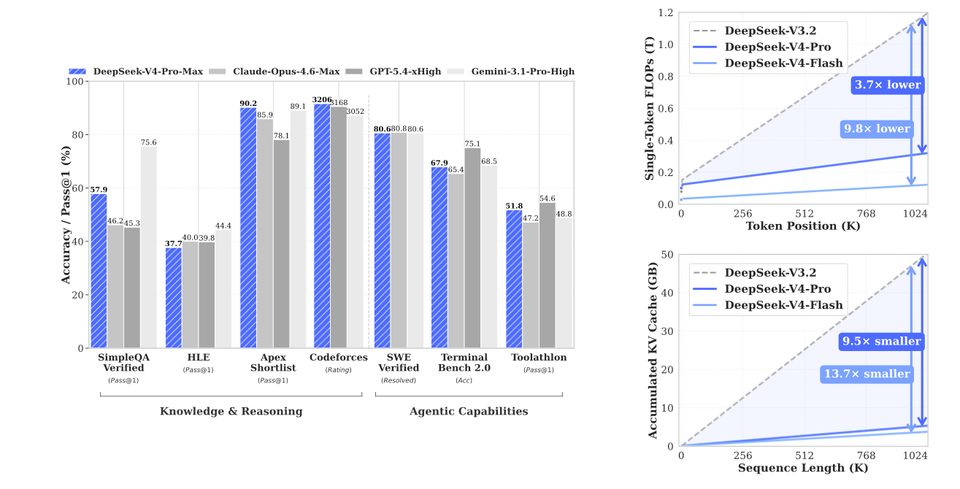
Согласно данным из документа, при обработке контекста в миллион токенов модель требует лишь около 27% вычислений на один токен по сравнению с предыдущей версией DeepSeek-V3.2, а объём используемого KV-кеша сокращается до 10%. И это не косметическое улучшение, а почти десятикратный выигрыш по памяти в отдельных сценариях.
Этот результат достигается не только за счёт внимания, но и благодаря целому ансамблю инженерных решений: от нового оптимизатора Muon, ускоряющего сходимость обучения, до сложной системы параллелизма и даже экспериментов с FP4-квантизацией, которая намекает на будущее аппаратного со-дизайна ИИ.
Иными словами, DeepSeek делает то, чего индустрия долго избегала: оптимизирует не только модель, но и всю инфраструктуру вокруг неё.
Архитектура как поле битвы
Если попытаться заглянуть глубже, становится ясно, что главный конфликт здесь проходит не между компаниями, а между подходами.
DeepSeek V4 сохраняет знакомую основу Transformer, но насыщает её новыми элементами — от Manifold-Constrained Hyper-Connections, которые стабилизируют обучение глубоких сетей, до усложнённой MoE-архитектуры с триллионными параметрами, из которых активируется лишь малая часть.
В версии DeepSeek-V4-Pro речь идёт о 1,6 триллиона параметров, из которых в каждый момент задействовано около 49 миллиардов. Это звучит как компромисс, но на деле является стратегией: модель остаётся огромной по потенциалу, но экономной в использовании.
Именно здесь проявляется новая идеология — не brute force, а селективная мощность.
Между догоняющим и лидером
Любопытно, что сами авторы не пытаются выдать DeepSeek V4 за абсолютного лидера. В ряде задач модель всё ещё немного уступает передовым закрытым решениям, вроде последних версий GPT и Gemini, отставая примерно на несколько месяцев в развитии.
Однако в этом признании кроется куда более важная деталь: разрыв сокращается, и сокращается быстро.
В тестах на длинный контекст и агентные задачи DeepSeek V4 не просто догоняет, а в отдельных случаях обходит конкурентов, особенно в условиях экстремально длинных входных данных. И если раньше open-source модели играли роль лабораторных альтернатив, то теперь они всё чаще становятся практическими инструментами.
Тихая революция, которую легко не заметить
История DeepSeek V4 — это не про очередной «самый умный ИИ». Это история о смене парадигмы, происходящей почти незаметно.
Пока рынок обсуждает, кто быстрее и мощнее, DeepSeek задаёт другой вопрос: как сделать интеллект доступнее, дешевле и масштабируемее в реальном мире. И если эта стратегия окажется жизнеспособной, индустрия может столкнуться с неожиданным сценарием — не с технологическим скачком, а с медленным, но неотвратимым перераспределением сил.
В этом смысле DeepSeek V4 звучит не как вызов, а как предупреждение: будущее ИИ, возможно, будет определяться не теми, кто строит самые большие модели, а теми, кто умеет делать их по-настоящему эффективными.




Комментарии ()